
Linux下的压缩和解压——gzip编码逆向解析
我们知道在linux下最重要的打包工具和压缩工具是tar和gzip。对他们我们用得非常熟练,但是对其底层编码原理我们却知之甚少,本文我们就通过xxd手动反推解析gizip二进制文件来了解其底层编码原理。

开始
让我们制作一个gzip压缩文件,看看里面有什么。我们将保持简单:只需将8个字符串“aaaaaaaa”写入到文件。
echo "aaaaaaaa" >hello.out用xxd查看二进制内容:
xxd hello.out
0000000: 6161 6161 6161 6161 0a aaaaaaaa.如上所示,文件有9字节长。8个字节的“aaaaaaaa”,结尾写入了一个换行(LF)字符。
gzip编码头
用gzip对其压缩。我们选用gzip -1,这是最快的压缩模式。gzip命令的详细使用方法不再赘述,基本命令参数如下:

gzip -1 hello.out
继续用xxd查看二进制内容:
xxd hello.out.gz
0000000: 1f8b 0808 9494 a061 0403 6865 6c6c 6f2e ....'..a..hello.
0000010: 6f75 7400 4b4c 8400 2e00 b666 d7ad 0900 out.KL.....f....
0000020: 0000内容分析:
前几个字节非常简单:
1f8b:是gzip文档格式,硬编码的gzip标头。
08:表示DEFLATE压缩方法。
08(00001000):位3被设置,所以是一个文件名。
9494 a061:2021-11-26日星期五16:28:12。
04,表示压缩是使用最快的算法(-1标志的)。
03,Unix操作系统(LF/CLRF)。
接下来的几个字节对应的是文件名: 。
6865 6c6c 6f2e 6f75 74 00
h e l l o . o u t NUL压缩数据
数据从字节0x13开始,以4b开头的为压缩的数据要解码,需要查看各个位,因为DEFLATE将信息打包成可以跨越字节边界的位。具有5位或9位代码的情况并不少见。
xxd -s 21 -b test.out.gz
0000013: 00000000 01001011 01001100 10000100 00000000 00101110 .KL...
0000019: 00000000 10110110 01100110 11010111 10101101 00001001 ..f...
000001f: 00000000 00000000 00000000接着来分解一下。xxd 将字节一个一个地打印出来,其顺序为MSB到LSB。但是在gzip 中,字节被打包是LSB到MSB顺序的。所以必须逐字节反转字符串。
解码块
8bitswise: 11010010 00110010 00100001 00000000 01110100 00000000
转化后: 1 10 10010001 10010001 0000100 00000 00111010 0000000 00- 用固定的霍夫曼代码压缩(不要忘记,虽然比特流说“10”,但它被读为01,因为数据文本将以小端格式解释)
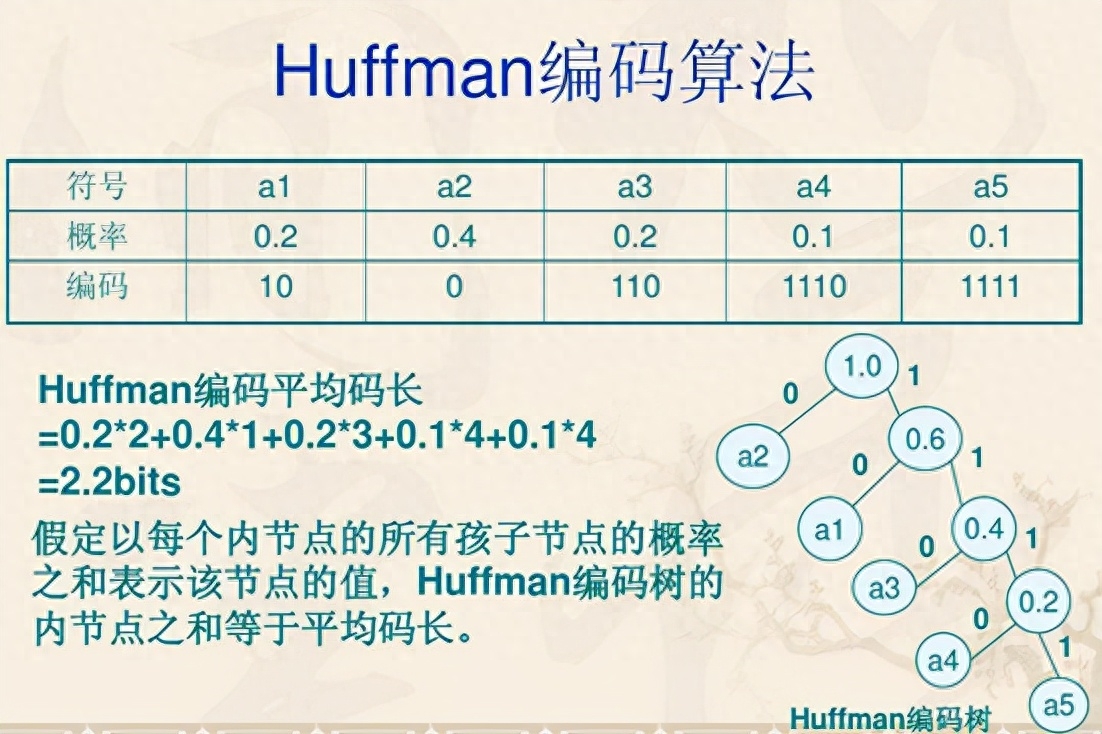
接下来解码霍夫曼码。固定霍夫曼码(又名静态霍夫曼码)的要点是它们是一堆经过商定的霍夫曼码,长度范围为7-9位。与所有霍夫曼代码一样,每个代码都是无前缀的,这意味着当一点一点地读取比特流时,每个代码何时结束都无任何歧义。
霍夫曼表规范中:
Lit Value Bits Codes
--------- ---- -----
0 - 143 8 00110000 through
10111111
144 - 255 9 110010000 through
111111111
256 - 279 7 0000000 through
0010111
280 - 287 8 11000000 through
11000111要解码霍夫曼码,必须(可能)读取接下来的9位。从一点一点地读取比特流开始,直到识别出一个唯一标识它是哪个字符的前缀。可以从概念上将其视为沿着霍夫曼树的边缘遍历下去。
接下来的9位是100100011-其前缀100,它表示这是0-143之间的文本。所以它只有8位 (1001 0001)。
霍夫曼代码将LSB打包为MSB,但将被解释为大端格式的整数。解码得到:
val = (10010001 - 00110000)=145-48=97。97是'a'ASCII码。 解码其余各字节得到:
1 10 10010001 10010001 0000100 00000 00111010 0000000 00
97 97 260 0 58 256 -
'a' 'a' repeat 6x 1 behind 0x10 (LF) HALT <padding>
LIT LIT LEN DIST LIT有8'a',两个’aa\后跟 6 'a'重复,然后是LF。
“repeat 6x, 1 behind”是一个长度+距离(LEN,DIST)的代码它告诉解码器要重复的字符是它刚刚解码的前一个字符。在这种情况下它是“a”。
已经将8 'a's 和 LF(最初是72 位)编码为46位和2个填充位。
校验和及大小
让我们完成gzip文件。接下来一个CRC32。看到带有换行符的未压缩 8 'a 将生成:ad d7 66 b6.十六进制流:
xxd hello.out.gz
0000000: 1f8b 0808 27a5 a061 0403 6865 6c6c 6f2e ....'..a..hello.
0000010: 6f75 7400 4b4c 8400 2e00 b666 d7ad 0900 out.KL.....f....
0000020: 0000 ^^^^^^^^^^可以清楚地看到 b6 66 d7 ad, 以小端字节顺序。为crc校验和。
接下来的4个字节09 00 00 00是9个字节的小端字节序。事实上,解码了9个字节,输入文件中有9个字节。
总结
整个压缩文件分析如下:
gzip info: 1f8b 0808 27a5 a061 0403
filename: 7465 7374 2e6f 7574 00
DEFLATE data: 4b 4c 84 00 2e 00
crc32: b6 66 d7 ad
size: 09 00 00 00以上我们通过对gzip二进制内容解析分析其具体编码过程,通过这样分析来让我们理解压缩和文件编码,当然gzip最重要的动态霍夫曼算法,相关内容感兴趣的同学可以自己去学习,也可以参考gzip源码学习具体代码实现过程,这就是后话了。
相关推荐
-
 linux之chsh命令2024-05-07 18:53:31
linux之chsh命令2024-05-07 18:53:31 -
Linux Namespace浅析2024-05-07 16:46:07
-
 Linux-多进程开发,看完就明白了2024-05-07 14:18:13
Linux-多进程开发,看完就明白了2024-05-07 14:18:13 -
 linux 安装vue 很简单2024-05-07 12:59:50
linux 安装vue 很简单2024-05-07 12:59:50 -
 在 Linux 上用 zram 替代传统交换空间2024-05-07 11:13:30
在 Linux 上用 zram 替代传统交换空间2024-05-07 11:13:30
