
MySQL学习:分库分表的原理
841人浏览 2023-10-23 15:04:47
概述
- 一个数据库的演进过程通常为在起初数据量不大,使用单个数据库节点就可以支持业务的读写访问。随着系统用户量的增加,数据库存储的数据量也随之增加,这个时候通常可以通过提升数据库主机的硬件来提升处理能力。
- 当提升硬件已经无法支撑访问量时,这个时候单台数据库同时处理读写请求会由于访问量过大而成为性能瓶颈。通常这个时候需要使用MySQL主从复制来实现读写分离,使用一个主库负责处理数据写请求,使用一个或多个从库处理读请求。
- 读写分离的架构通常适合于读多写少的应用场景,但是如果是写非常频繁的系统,如股票类在线交易系统,则由于读写分离架构中还是单个主库负责数据写入,故可能会存在性能瓶颈。
- 其次如果数据库数据量非常大,即使进行了读写分离,每个读写分离集群的每个节点需要保持大量数据,数据查询性能也会下降。同时主从复制也会由于需要复制大量的binlog而造成节点负载压力较大。
- 故如果由于数据库需要执行大量写请求而导致主库产生性能瓶颈,或者数据库存放的数据量太大导致查询性能下降和需要进行大量的binlog传输时,则需要考虑对数据库自身进行拆分,即采用分库分表的解决方案。
分库:数据垂直拆分
- 分库是基于系统的拆分来实现的,即对于一个大的系统,根据系统各模块的特性,拆分为多个子服务,每个子服务都是高内聚的。
- 对于系统原来的数据库,将每个拆分出来的子服务涉及的数据表拆分到对应的独立子数据库中。例如对于一个大的电商系统,则可以拆分为了用户服务,订单服务,物流服务等子服务,每个服务有自身的独立数据库。
- 分库示意图:(图片引自《MySQL性能调优和架构设计》)
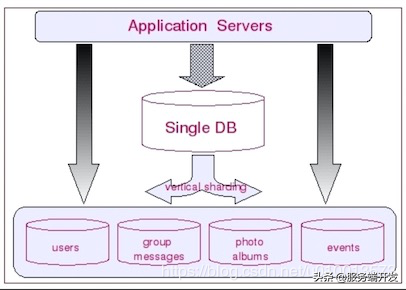
Join操作
- 在一个数据查询当中,通常会涉及数据库的多张数据表,所以需要通过SQL的join操作来进行拼表,但是进行分库之后可能这些表分散到了多个不同的子数据库中了,故需要对原有应用代码所使用的SQL进行修改,由原来的一条SQL查询对应的数据改为在应用代码中通过HTTP或者RPC的方式从各个子服务获取数据,然后在应用代码中进行数据组装。
- 所以进行分库之后,对于单个请求性能反而可能会下降,因为增加了不同主机之间的服务调用,网络请求。但是对于整个系统的整体性能和吞吐量则可以提高。因为拆分之后各个子服务并发执行而且速度更快,即使需要不同服务之间的网络通信调用,由于各个子服务调用都执行更快,故系统整体可以运行地更快。
- 如果原有系统数据表之间耦合度较低,每个系统子模块的内聚性比较好,很少进行join拼表查询,则就会减少不同子服务之间的调用和减少对原有应用代码的修改调整,故在数据库设计时,可以适度进行数据冗余存储,即适度地进行反范式设计来减少join的需要,保持各个子模块的内聚性,这样可以提供系统后期的可拓展性,如在进行微服务拆分和分库时,操作更加方便。
分布式事务
- 对于数据更新操作,如果更新的表都在一个数据库当中,则可以基于MySQL的Innodb存储引擎的事务机制来保证数据的一致性,而不需要在应用代码中进行这方面的考虑。
- 在进行分库之后,如果一次更新涉及到的表分散到了不同的子数据库中,则此时需要基于分布式事务来保证数据一致性。通常的做法是每个子数据库基于MySQL的事务机制来实现事务安全,在整体上需要在应用代码中保证所有子数据库都操作成功才执行,即整体的ACID。
- 分布式事务的实现方案:包括两阶段提交,基于消息队列实现等,具体后续分析。MySQL也提供分布式事务的实现XA。由于分布式事务需要涉及多个节点的事务,所以在性能方面相对于单机事务,事务执行所需时间比较长,故会增加数据更新操作的延时。
- 所以在进行分库时,要尽量减少分布式事务的需要,是否需要分布式事务也要作为是否将一个子服务进行继续拆分的考虑条件,即如果拆分后需要通过分布式事务来实现数据一致性,则此时可能不适合再进行拆分。
分表:数据水平拆分
- 分表主要在单个表或者多个表的每个的数据量都太大,导致查询速度过慢或者单机无法存储时使用。
- 分表主要是基于数据表的某个字段来将一个表拆分为多个子表,即一个表中的数据行拆分到多个子表中去保存,子表存放到同一个数据库的不同表或者不同的数据库中。
- 分表字段选择:
- 通常需要有明显区分效果的字段,如订单的时间或者订单的用户id,如果基于订单的时间,则可以以年为单位进行分表,每个子表保存同一年的订单;如果是基于用户id,则将用户id和子表数量取模来实现同一用户的订单都会落在同一个子表中;
- 分表操作除了需要考虑如何对单个表进行拆分之外,还需要考虑这个被拆分的表的其他关联表。即被拆分的表需要是当前业务的主表,这个主表的数据行被拆分到各个子表之后,每个子表的数据行与所关联的其他表的数据行需要在同一个数据库中,这样在更新时才能在一个数据库完成,否则分表后需要涉及不同数据库,则应用代码复杂度会非常高,调整修改非常大,而且很难维护。
- 通常如果是一个大系统的话,要保证被分表的表是业务主表,即可以关联所有其他表基本是不可能实现的,故需要先进行分库将大系统拆分为多个高内聚的子系统,每个子系统对应的数据库由一个主表关联其他表。然后再在子系统内部对主表进行分表操作。
- 举个例子,电商系统的订单表很大,故将订单表作为一个子系统拆分出来了,简单起见,假如该子系统只包含了订单表和订单项,其中订单表为主表。订单表很大,所以需要进行分表,可以基于订单的用户id来分表,即将订单子系统继续分到多个子数据库中,每个子数据库包含订单表和订单项目。每个子数据库的订单表包含原订单表的部分行,而在分表时,将订单表的数据行对应的订单项也分到同一个子数据库中,这样由于每个订单项只依赖于订单,即订单项的修改只能由订单触发,故不会存在一个订单的订单项出现在其他子数据库的问题。
- 分表示意图如下:
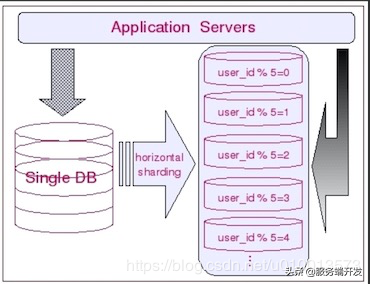
范围查询
- 分表之后如果涉及到对该表的范围查询,则需要从各个子表获取数据,所以通常是需要在应用代码中,连接各个子表所在的数据库,然后查询数据再在应用代码中汇总。
分库分表
- 分库分表通常不是独立存在,而是分库分表同时进行的,特别是对于分表来说,因为分表的目标对象是业务主表,这样各个子表的数据行所关联的其他数据行对应的数据表才能落在同一个子数据库中。而要提取出业务主表,则前提是系统拥有高内聚性。
- 即一般需要先进行分库拓展,保证各个子系统的高内聚,然后在分库拓展之后,如果还存在某些表数据量太大或者读写过于频繁,则需要进一步分表操作。具体已在上面分表字段选择部分进行了分析。
相关推荐
-
 mysqldump备份操作大全及相关参数详解2023-10-23 15:39:38
mysqldump备份操作大全及相关参数详解2023-10-23 15:39:38 -
Java,MySQL,主备复制原理,Canal,实现数据异构,Demo案例
Java,MySQL,主备复制原理,Canal,实现数据异构,Demo案例2023-10-23 15:39:26 -
 MySQL事务控制和锁定语句2023-10-23 15:37:22
MySQL事务控制和锁定语句2023-10-23 15:37:22 -
 MYSQL 登录与退出,查看当前数据库2023-10-23 15:37:06
MYSQL 登录与退出,查看当前数据库2023-10-23 15:37:06 -
 MySQL常用图形管理工具有哪些?2023-10-23 15:32:26
MySQL常用图形管理工具有哪些?2023-10-23 15:32:26